

InfluxData's Latest Updates Optimize Time Series Data for Better Performance, Scale and Management 
InfluxData's InfluxDB 3.0 time series data platform is adding new capabilities to power massive time series workloads at scale – and to be AI-ready. IDN talks with InfluxData CEO Evan Kaplan about the latest updates for performance, management and more.
by Vance McCarthy
Tags: AI, cloud, data cardinality, InfluxDB, monitor, real-time, time series, workloads,

CEO

"Today's applications demand more than just storage and analysis of time series data—they require the intelligence to adapt and respond in real-time."
 Modern Application Development for Digital Business Success
Modern Application Development for Digital Business SuccessInfluxData continues to extend key capabilities for its latest InfluxDB 3.0 time series data platform product suite to make it easier to manage projects at scale.
This month brings two key updates:
- General release of InfluxDB Clustered, InfluxData’s 3.0 offering for on-premises and private cloud environments; and
- InfluxDB Cloud Dedicated, a fully managed time series database-as-a-service for enterprise-grade workloads.
The updates come as customers are looking for options to run high-performing systems that can support expanding workloads, real-time use case, and high-resolution data retrieval and analysis, according to InfluxData CEO Evan Kaplan.
“Intelligent, real-time systems require an operational database capable of managing high-speed, high-resolution workloads,” Kaplan said. “InfluxDB 3.0 is engineered to meet this challenge head-on with industry-leading ingest performance, unlimited data cardinality, and exceptionally low latency querying, giving architects and developers tools to build real-time monitoring and control systems.”
Overall, the latest InfluxDB updates “allow developers to manage even higher-scale workloads without limits or compromising performance,” Kaplan added. In specific, they include:
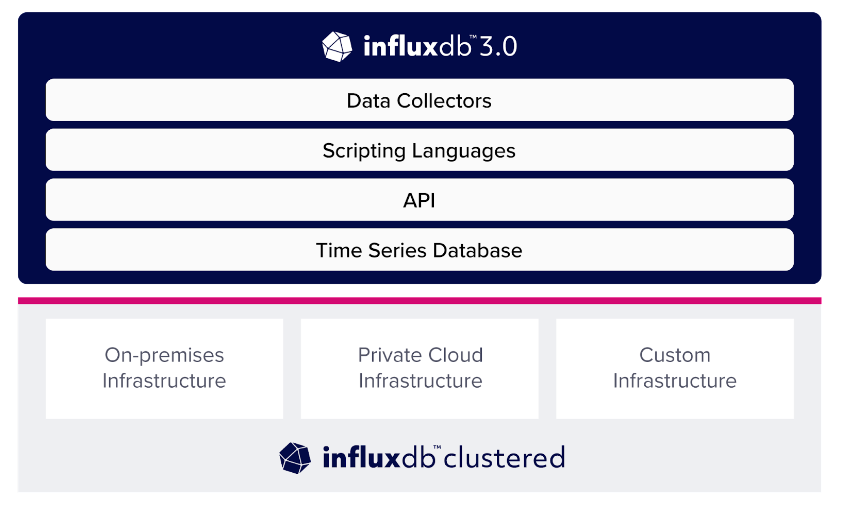
InfluxDB Clustered Goes GA: With support for on-premises and private cloud environments, InfluxDB Clustered is now generally available. Deployed on Kubernetes, it features decoupled, independently scalable ingest and query tiers, providing high availability and exceptional scalability.
By separating compute from storage, developers can precisely scale ingest and query components independently of their storage requirements, Kaplan said. In this GA release, customers gain all capabilities in the InfluxDB 3.0 core, as well as the option to use InfluxData’s new Helm Chart deployment method to support developers using Helm for deployments.
Updates to InfluxDB Cloud Dedicated: InfluxDB Cloud Dedicated, InfluxData’s fully managed time series database-as-a-service for enterprise-grade workloads, adds several key features, including:
- A new “operational dashboard” to give developers more comprehensive visual insights into performance and health of dedicated clusters. The update lets developers more easily detect unintended workload changes, identify potential bottlenecks, and optimize cluster performance.
- Single sign-on (SSO) integration, which will streamline the log-in process and provides seamless access to clusters using existing credentials, and
- New APIs for management & Token management lets users automate administrative tasks such as managing users, databases, and tokens within their InfluxDB Cloud Dedicated cluster.

InfluxDB Updates Meets Growing Need for ‘Real Time Intelligence’
There is a growing need for real time “intelligence” from data – beyond simple data storage, Kaplan said, adding that the implications of this shift are compelling – and exciting for application developers and users.
Today's applications demand more than just storage and analysis of time series data—they require the intelligence to adapt and respond in real-time. InfluxDB 3.0 is purpose-built to meet these challenges, offering the ability to handle high-cardinality datasets, dynamically scale, and perform real-time analysis. As developers increasingly rely on intelligent systems that predict, respond, and adapt instantly, InfluxDB 3.0 serves as the critical foundation, enabling a broader range of use cases and driving the future of real-time, adaptive applications.
Just a few years ago, traditional time series use cases primarily focused on monitoring infrastructure, application performance, or basic IoT deployments, where data was processed in batches and analyzed retroactively. The emphasis was on system reliability and performance, with scalability playing a role but not always being a critical factor. Data workloads were relatively predictable and manageable.
Today, the landscape has transformed significantly. Our customers are leveraging InfluxDB 3.0 to tackle far more complex and demanding scenarios. InfluxDB is now the foundation of real-time systems, handling millions—if not billions—of data points across a vast array of products, systems, and services.
With InfluxDB Clustered, deploying on Kubernetes offers our customers unparalleled flexibility; users can scale ingest and query capacity independently, customizing their deployment to workload demands. What’s more, users can scale up and down with seasonal or intermittent workloads. The shift toward real-time, scalable processing underscores the increasing demand for agility and immediate insights in high-resolution data environments.
Since InfluxDB 3.0’s release last year, it has offered developers unlimited cardinality, high-speed ingest, real-time querying, and superior data compression through native object storage to power high-cardinality use cases – such as observability, real-time analytics, and IoT/IIoT.
InfluxDB 3.0 Driven by ‘Evolving’ Needs of Customers
InfluxDB 3.0, customers also played a key role in the on-going expansion of time series capabilities, Kaplan added.
InfluxDB 3.0 was driven by a combination of our vision and the evolving needs of our customers.
From the start, we envisioned InfluxDB as more than just a time series database; we saw it as a comprehensive platform for storing and analyzing raw events, observational data, and any historical data at scale. The goal was to create a database capable of handling a wide range of analytic tasks, from real-time insights to large-scale historical analysis.
Our customers played a crucial role in shaping this vision. They asked for features that would make InfluxDB 3.0 even more powerful and flexible for their use cases:
- Support for high-cardinality data was high on the list, enabling the simultaneous execution of complex analytical queries across many time series.
- Cost-effective storage, specifically the ability to use cheaper object storage for historical data.
- Integrations with a broader set of third-party tools, particularly through SQL as a first-class query language.
Meeting these customer needs promoted InfluxData architects to think more broadly about time series – beyond a simple data store to a more fully-featured platform, Kaplan added.
We knew that delivering on these requests required more than incremental improvements—it necessitated a complete re-architecture of our underlying database. Building InfluxDB 3.0 on the FDAP Stack (Flight, DataFusion, Arrow, Parquet) transformed the database’s performance, making it much faster and far more efficient, with a flexible architecture.
It delivers significant gains in ingest efficiency, scalability, data compression, storage costs, and query performance on higher cardinality data. The removal of cardinality limits means users can bring in unlimited amounts of time series data and analytical queries against many time series simultaneously, even as data complexity and cardinality increase.
Early feedback from customers using InfluxDB Clustered affirms its value for balancing needs for high-scale data, useful real-time analytics, ease-of-use and low cost.
“We rely on InfluxDB Clustered as the foundation of our customer usage monitoring solution, processing millions of time series data points collected across more than 40 distinct products and services,” said Arun Kesavan, Principal Engineer at Verint. “By deploying InfluxDB Clustered on Kubernetes, we gain the flexibility to effortlessly scale our systems in response to growing data workloads during peak usage. This allows us to analyze high-cardinality data in real-time at a significantly reduced cost, providing our team with critical insights faster than ever before.”
Time Series, Real-Time and AI: The Coming Convergence
And with this extended support for scale, real-time analytics and easy deployment, no surprise there are also use cases for AI. Kaplan explained to IDN the impact of InfluxDB 3.0 (and its partner ecosystem) on AI projects in detail.
As AI capabilities advance, the need for robust platforms to support intelligent, real-time systems becomes critical. InfluxDB 3.0 is a foundational platform that is elite at this use case by managing vast amounts of time series data in real-time.
AI models require continuous training; the data streams feeding these models never stop. This constant flow of high-volume, high-cardinality data demands a platform engineered to handle these challenges seamlessly. Consider a sensor that measures up to 50 different data points every millisecond. Now consider an autonomous car with as many as 40 sensors on it. Those sensors produce high-cardinality data that grows exponentially every minute. InfluxDB 3.0’s ability to manage high-speed ingestion, real-time querying, and efficient downsampling is essential in such scenarios, ensuring that the continuous data flow can be processed, analyzed, and acted upon in real-time.
Finally, time series databases like InfluxDB enable developers to leverage both fresh and historical data, uncovering real-time insights crucial for detecting problems, predicting outcomes, and triggering the correct automated responses.
As AI-driven systems become more prevalent, the ability to manage and analyze this data in real-time will be key to building long-term intelligence.
Looking ahead, the integration of Iceberg support will make data ingested in InfluxDB available to data lake houses and warehouses like Databricks and Snowflake. These advancements will further mature large-scale data analytics, real-time query capabilities, and enable the seamless integration of real-time data with warehouse and lakehouse systems, positioning InfluxDB as a cornerstone for the future of intelligent applications.
InfluxDB 3.0 commercial products are now generally available. To start leveraging the power of InfluxDB Clustered or InfluxDB Cloud Dedicated, contact InfluxData sales today.
Related:
- Actian Zen 16.0 Update Simplifies Delivery and Boosts Performance of Edge, IoT Apps
- Virtana Infrastructure Performance Management Adds AI-driven Capacity Planning
- e2open’s Supply Chain SaaS Updates Help Firms Reduce Operational Risks with Deeper Visibility
- Report: Endor Labs Identifies 2023 Operational, Security Risks To Open Source
- How Continuous Testing Can Help Organization Achieve Faster Releases
All rights reserved © 2024 Enterprise Integration News, Inc.